Bypassing GitHub's OAuth flow
For the past few years, security research has been something I’ve done in my spare time. I know there are people that make a living off of bug bounty programs, but I’ve personally just spent a few hours here and there whenever I feel like it.
That said, I’ve always wanted to figure out whether I’d be able to make a living on bug bounties if I chose to work on them full time. So I tried doing that for a couple months this summer, spending a few hours a day looking for security bugs in GitHub.
My main workflow was to download a trial version of GitHub Enterprise, deobfuscate it using a modified version of this script, and then just stare at GitHub’s Rails code for awhile to try to spot anything weird or exploitable. Overall, GitHub’s code seems very well-architected from a security perspective. I would occasionally find a bug caused by an unhandled case in some application logic, only to realize that the bug didn’t create a security issue because (e.g.) the code was running a query with reduced privileges anyway. Almost every app has bugs, but one big challenge of security engineering is to make bugs unexploitable without knowing where they are, and GitHub seems to do a very good job of that.
Even so, I managed to find a few interesting issues over the summer, including a complete OAuth authorization bypass.
GitHub’s OAuth Flow
At one point in June, I was looking at the code that implements GitHub’s OAuth flow. Briefly, the OAuth flow is supposed to work like this:
- Some third-party application (“Foo App”) wants to access a user’s GitHub data. It sends the user to
https://github.com/login/oauth/authorizewith a bunch of information in the querystring. -
GitHub displays an authorization page to the user, like the one below.
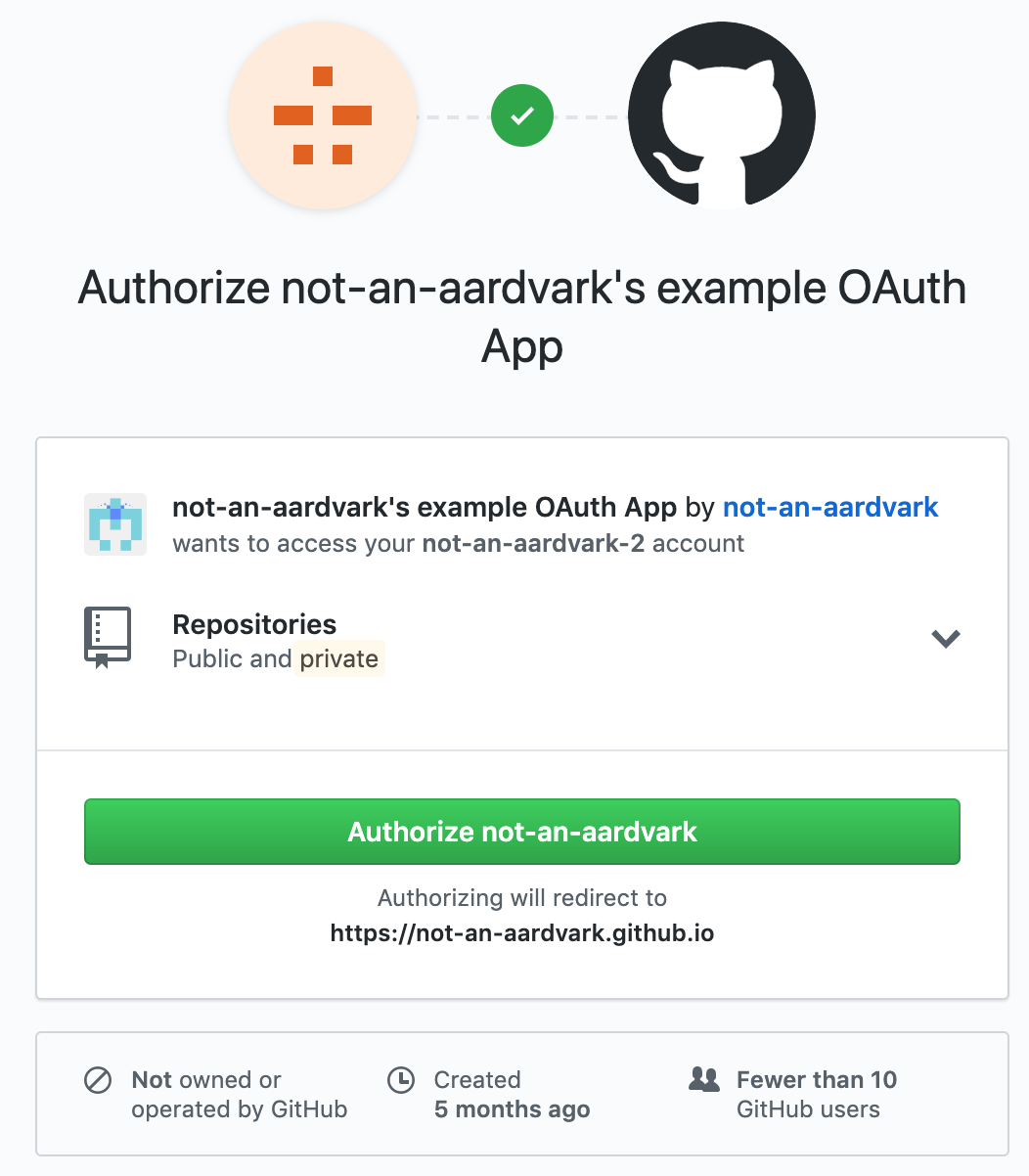
- If the user chooses to grant access to the app, they click the “Authorize” button on the page and are redirected to Foo App with an authorization code in the querystring. This code can then be used to access the requested data. (The user can also decline to give their data to the app.)
When reviewing this, I took a look at how the “Authorize” button is implemented. It turns out that the button is actually a self-contained HTML form that sends a POST request with some hidden form fields, including a CSRF token. When that POST request is sent (and the CSRF token is validated), the user is considered to have granted permissions to the app. Seems reasonable so far.
Interestingly, the endpoint URL for the “Authorize” button is /login/oauth/authorize, which happens to be the same as the URL for the authorization page itself. GitHub figures out which response to send based on the HTTP request method (GET requests return the HTML authorization page, and POST requests grant permissions to the app).
This behavior switch actually happens within application code. The router forwards both GET and POST requests to the same controller:
# In the router
match "/login/oauth/authorize", # For every request with this path...
:to => "[the controller]", # ...send it to the controller...
:via => [:get, :post] # ... as long as it's a GET or a POST request.
# In the controller
if request.get?
# serve authorization page HTML
else
# grant permissions to app
end
So the router accepts either a GET or a POST request, and the controller checks which type of request was sent and behaves accordingly. At first glance, this doesn’t seem like a problem – and it wouldn’t be, except that the router isn’t telling the truth.
HTTP HEAD requests, and why the Rails router sometimes lies
Let’s talk about HTTP methods.
The HTTP HEAD method has been around since HTTP was originally created, but it doesn’t get a lot of use. When a server receives a HEAD request, the expected semantics are, “pretend this is a GET request, but only send back response headers without a response body”. This has a few niche uses. For example, a client can send a HEAD request to check the size of a large file (via the Content-Length response header) before deciding whether it wants to start downloading the file.
Naturally, people writing web apps usually don’t want to take the time to implement behavior for HEAD requests. Getting a product that works is understandably considered more important than compliance with niche parts of the HTTP spec. But in general, it’s nice if HEAD requests can be processed correctly, provided that app developers don’t have to deal with them manually. So Rails (along with some other web frameworks) implements a clever hack: it tries to route HEAD requests to the same place as it would route GET requests. Then it runs the controller code, and just omits the response body.
So that’s nice, but it’s a leaky abstraction. If a controller calls request.get? on a request like this, it will return false, because it’s still a HEAD request, not a GET request.
Abusing HEAD requests
What happens if we send an authenticated HEAD request to https://github.com/login/oauth/authorize? We’ve concluded that the router will treat it like a GET request, so it will get sent to the controller. But once it’s there, the controller will realize that it’s not a GET request, and so the request will be handled by the controller as if it was an authenticated POST request. As a result, GitHub will find the OAuth app specified in the request, and grant it access to the authenticated user’s data.
Why is this useful? Well, GitHub’s CSRF protection requires all authenticated POST requests to include a CSRF token. But HEAD requests don’t need a CSRF token, since they’re not supposed to have side-effects. So we can send a cross-site authenticated HEAD request that will give arbitrary OAuth permissions, without showing the user a confirmation page at all.
As a result, if a user visited an attacker’s website, the attacker could arbitrarily read or modify private data in the user’s GitHub account. Here’s a proof-of-concept (which no longer works because the issue has been patched).
I reported this issue to GitHub’s bug bounty program, and they shipped a fix to production in about three hours. I also got a $25000 bounty (!), which at the time was the highest bounty ever from GitHub’s program.
Timeline
- 2019-06-19 23:28:56 UTC Issue reported to GitHub on HackerOne
- 2019-06-19 23:36:50 UTC Issue confirmed by GitHub security team
- 2019-06-20 02:44:29 UTC Issue patched on github.com, GitHub replies on HackerOne to double-check that the patch fully resolves the issue
- 2019-06-26 16:19:20 UTC GitHub Enterprise 2.17.3, 2.16.12, 2.15.17, and 2.14.24 released with the patch (see GitHub’s announcement).
- 2019-06-26 22:30:45 UTC GitHub awards $25000 bounty